
「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?
「越狱」事件频发,如何教会大模型「迷途知返」而不是「将错就错」?大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
来自主题: AI技术研报
10379 点击 2024-07-30 16:55
 搜索
搜索
大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。

自回归训练方式已经成为了大语言模型(LLMs)训练的标准模式, 今天介绍一篇来自阿联酋世界第一所人工智能大学MBZUAI的VILA实验室和CMU计算机系合作的论文,题为《FBI-LLM: Scaling Up Fully Binarized LLMs from Scratch via Autoregressive Distillation》

随着大型语言模型(LLMs)的进步,多模态大型语言模型(MLLMs)迅速发展。它们使用预训练的视觉编码器处理图像,并将图像与文本信息一同作为 Token 嵌入输入至 LLMs,从而扩展了模型处理图像输入的对话能力。这种能力的提升为自动驾驶和医疗助手等多种潜在应用领域带来了可能性。
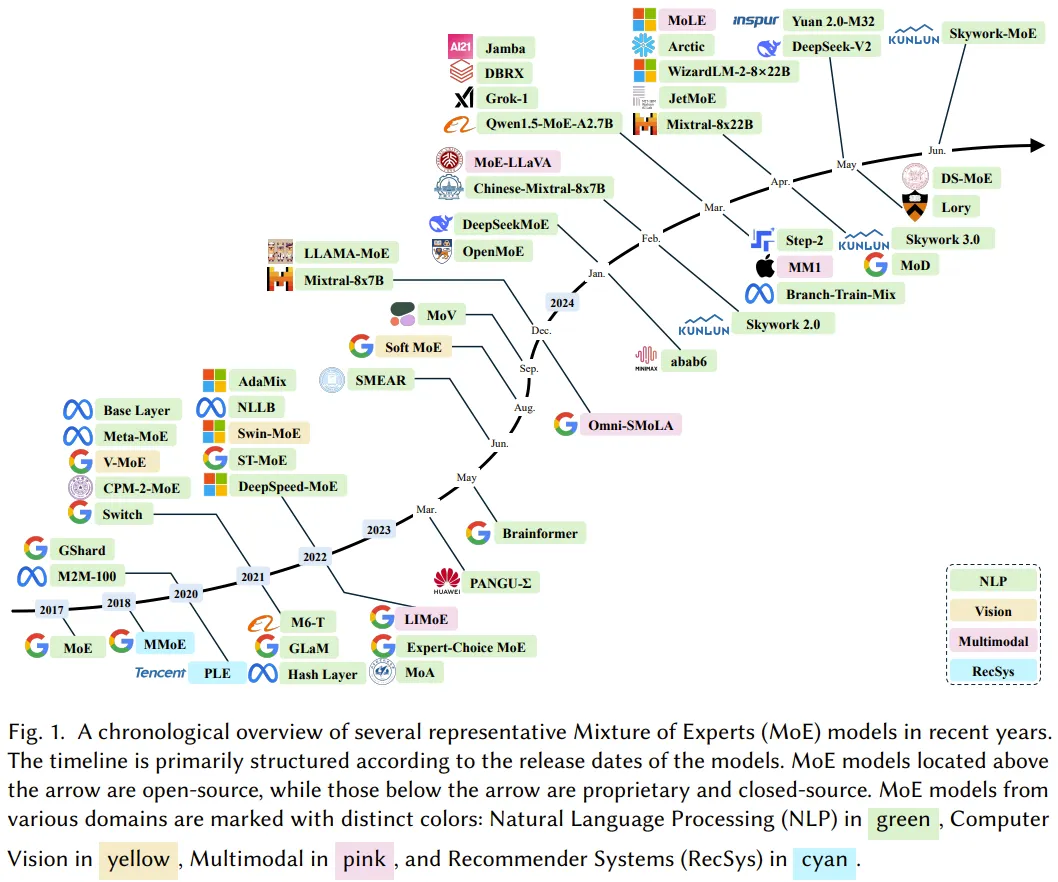
LLM 很强,而为了实现 LLM 的可持续扩展,有必要找到并实现能提升其效率的方法,混合专家(MoE)就是这类方法的一大重要成员。
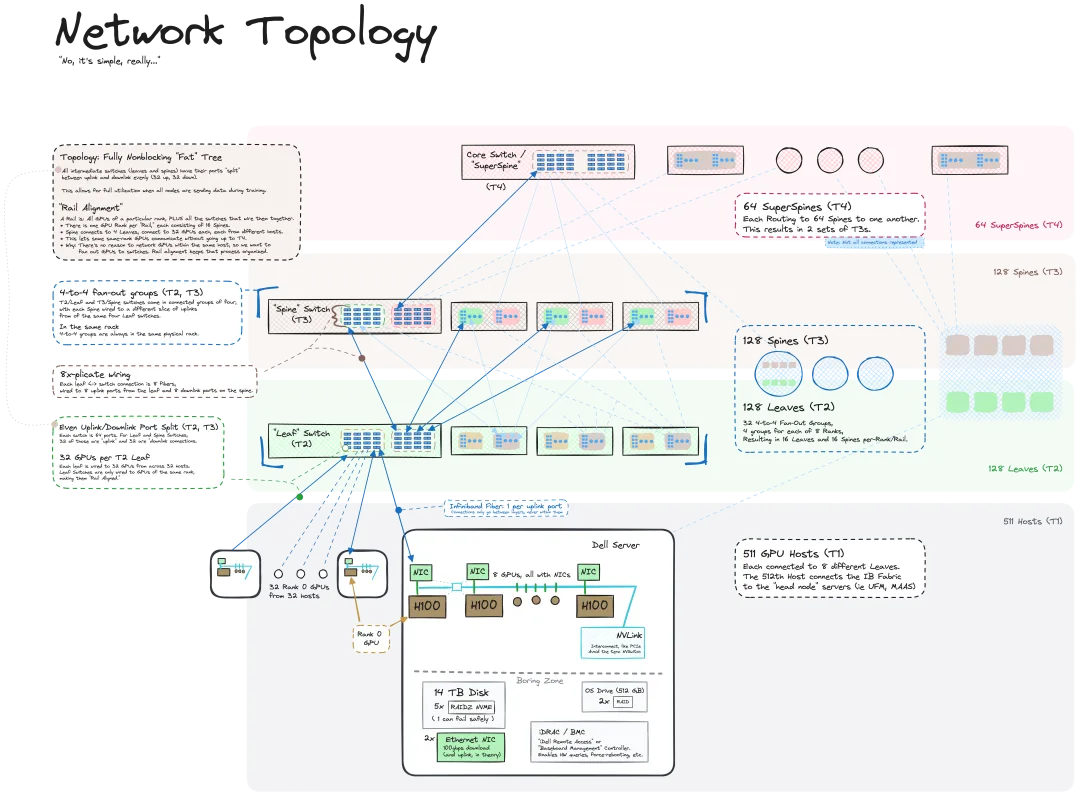
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。
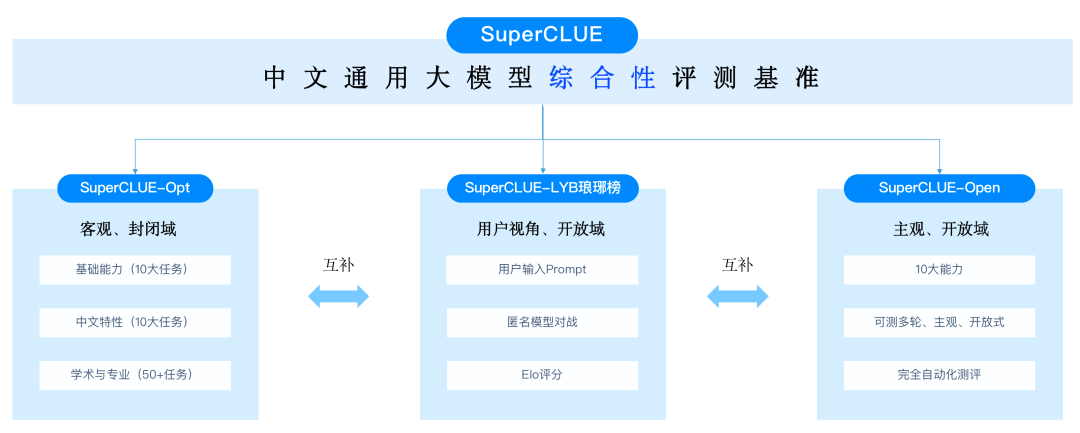
基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。
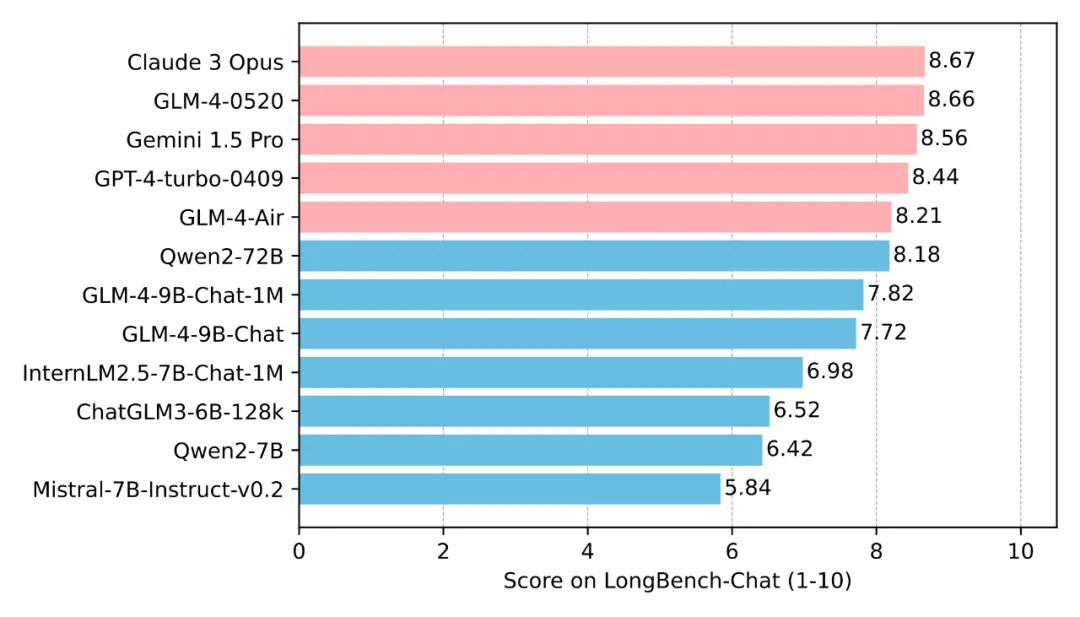
在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。

具身智能是过去一年中和 LLM 一样受到市场高度关注的领域,通用机器人领域什么时候会出现「iPhone 时刻」?这是所有人都关注的问题。拾象团队在过去一年中也深度追踪通用机器人和机器人 foundation model 的进展。本篇文章是我们对机器人领域研究的开源。

把因果链展示给 LLM,它就能学会公理。